9 minutes
Building a Step Function with Error Handling in AWS with Terraform
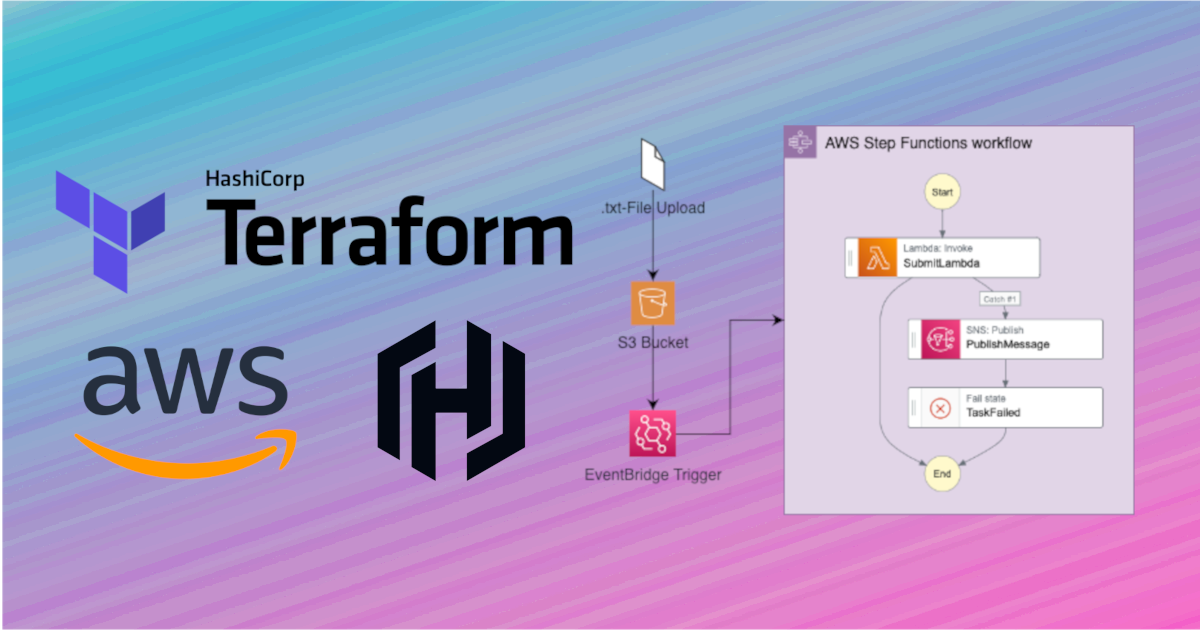
The automation of cloud infrastructure through code (also called Infrastructure as Code or IaC) let’s you define and manage cloud resources in a robust and repeatable way. One popular IaC frameworks is Terraform, which is cloud-agnostic and allows developers to define infrastructure for different cloud providers like Amazon Web Services (AWS), Microsoft Azure and Google Cloud Platform (GCP).
In this blog post, I will show you how to create AWS resources using Terraform and the HashiCorp Configuration Language (HCL). I will define a simple workflow that demonstrates the creation of several AWS resources:
- An S3 bucket with an event trigger
- A Step Function that will be triggered by the S3 bucket
- An SNS topic for error notifications
- A Lambda function that will fail (for the sake of the example)
The resources are designed to execute the following tasks: When a file with a .txt extension is uploaded to an S3 bucket, it triggers a Step Function execution that invokes a Lambda function. This Lambda function deliberately generates an error to showcase error handling. If the Lambda function fails, the Step Function manages the process by sending a notification to a predefined topic. This topic, subscribed to an email address, ensures the error message is delivered to the intended recipient.
This will hopefully be a good kickstart to build more complex use cases!
Getting Started
To follow along with this tutorial, you will need to have the following:
- An AWS account
- AWS CLI installed and configured
- Terraform installed
This tutorial also assumes basic familiarity with AWS and Terraform. If you need to refresh your memory or start off fresh from the very basics, these resources might help you:
If you want to follow along with the exact same example your can check out my GitHub repository .
Let’s get started.
Project Overview
In this tutorial, we will define our AWS resources in different modules that contain our terraform files written in HCL.
.
├── README.md
├── config.tf
├── main.tf
├── modules
│ ├── cloudwatch
│ │ └── cloudwatch.tf
│ ├── lambda
│ │ ├── lambda.tf
│ │ └── scripts
│ │ └── test_failure.py
│ ├── s3
│ │ └── s3.tf
│ ├── sns
│ │ └── sns.tf
│ └── stepfunction
│ └── stepfunction.tf
├── (terraform.tfvars)
├── (variables.tf)
└── (outputs.tf)
A main.tf-file serves as an entry point for our terraform application, in which we initialize the different variables, as well as modules and outputs.
variable "aws_region" {
description = "aws region to deploy resources in"
type = string
default = "eu-central-1"
sensitive = true
}
variable "aws_profile" {
description = "the aws profile to use for the credentials"
type = string
sensitive = true
}
variable "email_address" {
description = "the email address where sns sends failure messages to"
type = string
sensitive = true
}
# Modules
module "lambda" {
source = "./modules/lambda"
}
module "stepfunction" {
source = "./modules/stepfunction"
lambda_arn = module.lambda.lambda_arn
topic_arn = module.sns.topic_arn
}
module "cloudwatch" {
source = "./modules/cloudwatch"
stepfunction_arn = module.stepfunction.stepfunction_arn
bucket_arn = module.s3.bucket_arn
}
module "sns" {
source = "./modules/sns"
email_address = var.email_address
}
module "s3" {
source = "./modules/s3"
}
# Outputs
output "lambda_arn" {
value = module.lambda.lambda_arn
}
output "topic_arn" {
value = module.sns.topic_arn
}
output "stepfunction_arn" {
value = module.stepfunction.stepfunction_arn
}
output "bucket_arn" {
value = module.s3.bucket_arn
}
The file- and foldernames could of course be different for your project. You could for example very well store your variables in a file called variables.tf and the outputs in a file called outputs.tf. This differentiation can certainly be useful for larger projects.
Defining the AWS Resources with Terraform
The actual Step Function and Definition
Now, let’s define the core component of our simple workflow: the Step Function. This Step Function is designed to start by invoking a Lambda function, which, in the event of a failure, will publish a message to an SNS topic.
Remember, when using Terraform, it’s essential to define AWS IAM roles and policies to specify the permissions required by our resources, such as invoking a particular Lambda function and publishing to a specific SNS topic.
# variables
variable "lambda_arn" {}
variable "topic_arn" {}
resource "aws_iam_role" "role_for_sfn" {
name = "role_for_sfn"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "states.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}
EOF
}
resource "aws_iam_policy" "policy_for_sfn" {
name = "policy_for_sfn"
path = "/"
description = "My policy for sfn"
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "lambda:InvokeFunction",
"Resource": [
"${var.lambda_arn}",
"${var.lambda_arn}:*"
],
"Effect": "Allow"
},
{
"Action": "sns:Publish",
"Resource": "${var.topic_arn}",
"Effect": "Allow"
}
]
}
EOF
}
resource "aws_iam_role_policy_attachment" "attach_iam_policy_to_iam_role" {
role = aws_iam_role.role_for_sfn.name
policy_arn = aws_iam_policy.policy_for_sfn.arn
}
resource "aws_sfn_state_machine" "sfn_state_machine" {
name = "TfStateMachine"
role_arn = aws_iam_role.role_for_sfn.arn
definition = <<EOF
{
"StartAt": "TfSubmitJob",
"States": {
"TfSubmitJob": {
"End": true,
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException"
],
"IntervalSeconds": 2,
"MaxAttempts": 6,
"BackoffRate": 2
}
],
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "TfPublishMessage"
}
],
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "${var.lambda_arn}",
"Payload.$": "$"
}
},
"TfPublishMessage": {
"Next": "TaskFailed",
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"TopicArn": "${var.topic_arn}",
"Message.$": "$.Cause"
}
},
"TaskFailed": {
"Type": "Fail"
}
}
}
EOF
}
# outputs
output "stepfunction_arn" {
value = aws_sfn_state_machine.sfn_state_machine.arn
}
Yeah, I know, these inline json defining can look quite confusing. But the end-result is nothing more, than a pretty simple straight-forward step function.
Configuring the S3 Bucket with Trigger
As mentioned, we want this step function to be triggered by an upload of a file to an S3 bucket. Let’s define this bucket in the s3.tf file:
resource "aws_s3_bucket" "bucket" {
bucket = "tf-simple-workflow-bucket"
force_destroy = true
}
resource "aws_s3_bucket_public_access_block" "example" {
bucket = aws_s3_bucket.bucket.id
block_public_acls = true
block_public_policy = true
ignore_public_acls = true
restrict_public_buckets = true
}
resource "aws_s3_bucket_notification" "bucket_notification" {
bucket = aws_s3_bucket.bucket.id
eventbridge = true
}
# outputs
output "bucket_arn" {
value = aws_s3_bucket.bucket.arn
}
Here, we first create an S3 bucket named tf-simple-workflow-bucket with force_destroy = true, which means that the bucket will be destroyed when we delete the stack with terraform destroy or change the name of the bucket. We also enable eventbridge = true so that we can put a trigger for the Step Function on the bucket.
Next, we will create this event trigger in the cloudwatch.tf file, which will invoke a Step Function execution when a file with the .txt extension is uploaded to the bucket.
variable "stepfunction_arn" {}
variable "bucket_arn" {}
data "aws_iam_policy_document" "allow_cloudwatch_to_execute_policy" {
statement {
actions = [
"sts:AssumeRole"
]
principals {
type = "Service"
identifiers = [
"states.amazonaws.com",
"events.amazonaws.com"
]
}
}
}
resource "aws_iam_role" "allow_cloudwatch_to_execute_role" {
name = "aws-events-invoke-StepFunction"
assume_role_policy = data.aws_iam_policy_document.allow_cloudwatch_to_execute_policy.json
}
resource "aws_iam_role_policy" "state_execution" {
name = "state_execution_policy"
role = aws_iam_role.allow_cloudwatch_to_execute_role.id
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1647307985962",
"Action": [
"states:StartExecution"
],
"Effect": "Allow",
"Resource": "${var.stepfunction_arn}"
}
]
}
EOF
}
resource "aws_cloudwatch_event_rule" "stf_trigger_rule" {
name = "stf_trigger_rule"
event_pattern = <<EOF
{
"detail-type": ["Object Created"],
"resources": ["${var.bucket_arn}"],
"detail": {
"object": {
"key": [{
"suffix": ".txt"
}]
}
},
"source": ["aws.s3"]
}
EOF
}
resource "aws_cloudwatch_event_target" "cloudwatch_event_target" {
rule = aws_cloudwatch_event_rule.stf_trigger_rule.name
arn = var.stepfunction_arn
role_arn = aws_iam_role.allow_cloudwatch_to_execute_role.arn
}
A Dummy Lambda Function
In this example, a Lambda function that intentionally raises an error serves as a placeholder for the actual processing that could be implemented for your specific use case. With Terraform the following resources in a file called lambda.tf, that resides in the lambda module.
# for zipping the lambda
data "archive_file" "python_lambda_package" {
type = "zip"
source_file = "${path.module}/scripts/test_failure.py"
output_path = "${path.module}/scripts/test_failure.zip"
}
resource "aws_iam_role" "iam_for_lambda" {
name = "iam_for_lambda"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}
EOF
}
resource "aws_lambda_function" "test_failure_lambda" {
# If the file is not in the current working directory you will need to include a path.module in the filename.
filename = "${path.module}/scripts/test_failure.zip"
function_name = "TfFailureLambda"
role = aws_iam_role.iam_for_lambda.arn
handler = "test_failure.lambda_handler"
source_code_hash = data.archive_file.python_lambda_package.output_base64sha256
runtime = "python3.9"
}
# outputs
output "lambda_arn" {
value = aws_lambda_function.test_failure_lambda.arn
}
The lambda function is written in Python and sits in a file called test_failure.py in the ./modules/lambda/scripts folder.
#!/usr/bin/python3.9
def lambda_handler(event, context):
# here only an error is raised, normally a processing workflow could take place here
# e.g. the file is downloaded from s3, then processed and a return value is given based on the content
region = event["region"]
time = event["time"]
bucket = event["detail"]["bucket"]["name"]
file = event["detail"]["object"]["key"]
raise RuntimeError(f"Hey, something went wrong with your step function... Please check the latest execution! Details: File {file} was uploaded to bucket {bucket} in region {region} at {time}.")
Configuring SNS for Error Notification
Almost there! Before deploying, it’s important to set up a mechanism to handle unexpected errors that might occur during the runtime of our Step Function. Constantly monitoring the AWS console isn’t practical, so it’s far more convenient to receive a notification (e.g., an email) if something goes wrong. To achieve this, we’ll create an SNS topic and add an email subscription with our address to receive these notifications. This setup will be defined in a file named sns.tf.
variable "email_address" {}
resource "aws_sns_topic" "failure_topic" {
name = "TfFailureTopic"
}
resource "aws_sns_topic_subscription" "failure_topic_target" {
topic_arn = aws_sns_topic.failure_topic.arn
protocol = "email"
endpoint = var.email_address
}
# outputs
output "topic_arn" {
value = aws_sns_topic.failure_topic.arn
}
Deployment
Now, if you have your AWS account, credentials and Terraform all set up correctly, you should be ready to deploy the resources to your account using the usual terraform init, terraform plan and then finally terraform apply commands. If you haven’t put your secret values for the variables aws_region, aws_profile and email_address into a file called terraform.tfvars, we will be prompted for these variables, and then terraform will deploy our resourcess to AWS.
Testing the Infrastructure
To test our newly created infrastructure, we can upload a file with the .txt extension to our S3 bucket using the AWS Management Console or the AWS CLI:
touch test.txt
aws s3 cp test.txt s3://tf-simple-workflow-bucket
This triggers our step function and in turn invoke the Lambda function. If everthing goes right, it will throw an error. Our SNS topic should then receive a notification displaying the error message, which is forwarded to the email address we specified during deployment.
Conclusion
In this blog post, we explored how to use Terraform and HCL to provision AWS resources as code. We built a straightforward yet highly effective workflow that uses an S3 bucket trigger to start a Step Function, which then invokes a Lambda function. Additionally, we demonstrated how to leverage SNS to receive notifications in the event of Lambda function failures.
Using Terraform allows us to define our infrastructure as code, which provides several benefits such as version control, automated testing, and simplified deployment. Getting familiar with Terraform can be demanding with a steep learning curve, but might be useful for your purposes, as it can help you with other cloud providers like Microsoft Azure or Google Cloud Platform as well.